The Kernel is responsible for executing the code contained in your notebook. This includes both the code you write as a researcher and the code auto generated by the Dataset Builder Tool or Snippets. Your Kernel can die for a few reasons but the main one is when the command is too large to execute based on the allocated compute resources. For example, if a dataset is built with 500k rows and 50 columns, the Kernel will be unable to execute and automatically die when trying to load this dataset into the notebook. The two resolutions would be to either decrease the size of your dataset, or increase your allocated compute resources.
To decrease the size of your dataset you can leverage the Cohort Builder and Dataset Builder Tools. With the Cohort Builder, you can decrease the size of your overall cohort by adding inclusion and exclusion criteria. Using the Dataset Builder, you can create specific concept sets that exclude any unneeded columns. This will decrease both the amount of rows and columns in your dataset. Here are the Cohort Builder and Dataset Builder support articles.
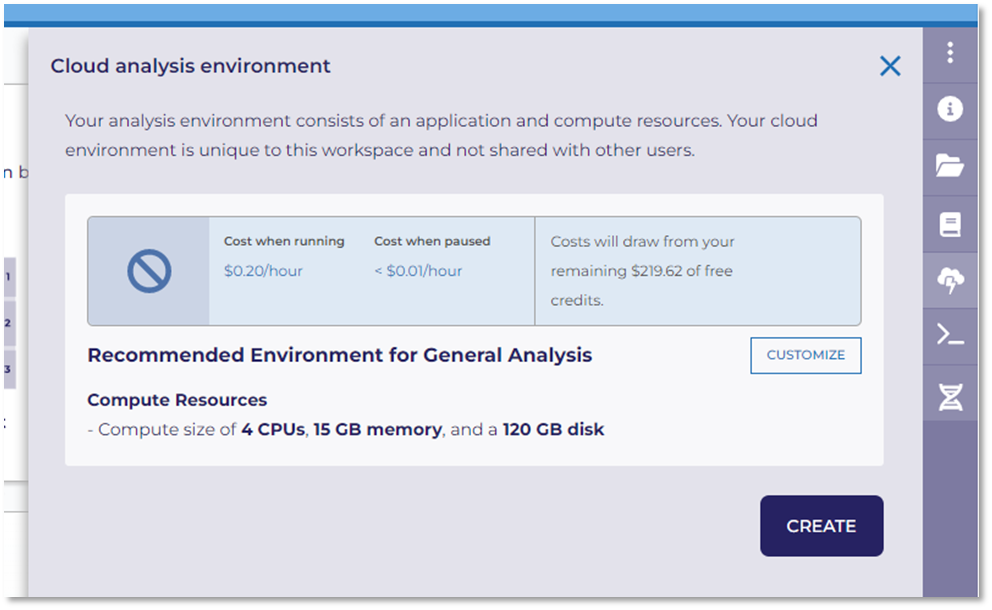
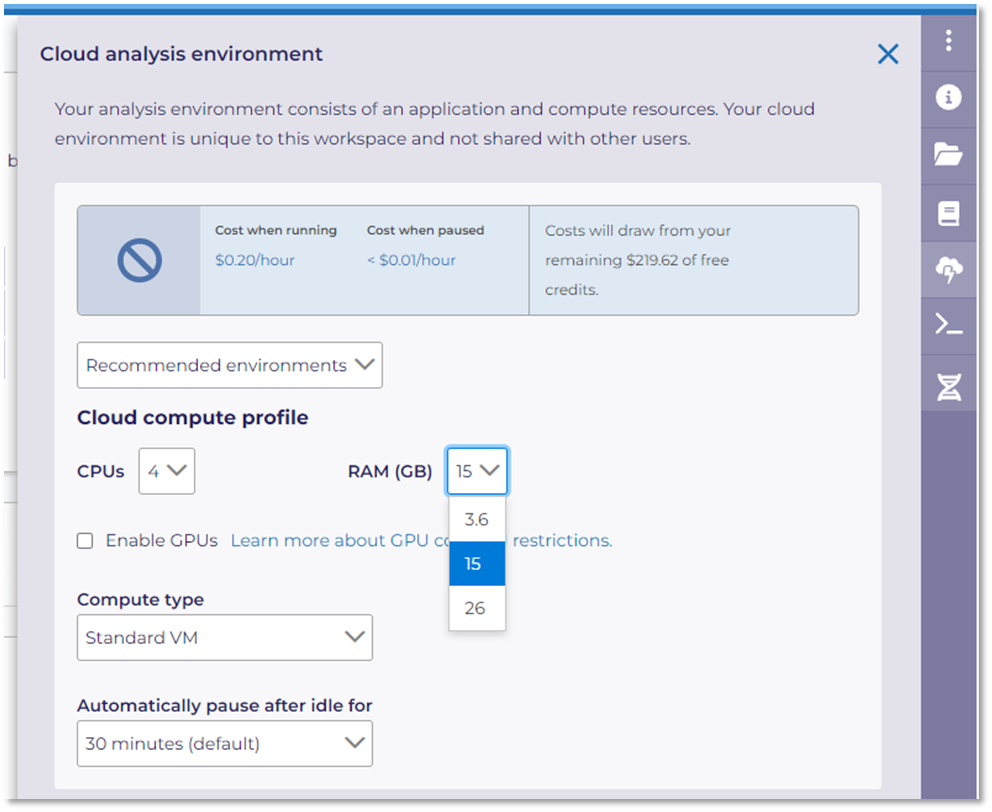
To increase your allocated compute resources you will need to navigate to the Cloud Analysis Environment terminal (thunder cloud icon) found on the right hand side menu within your workspace. Within the terminal you can ‘customize’ your environment. To prevent the Kernel from dying you will need to increase your storage (RAM). NOTE: utilize this option only when you truly want to view this large amount of data, as increasing compute resources will also increase compute cost.
Comments
0 comments
Article is closed for comments.